
文件和函数
文件处理相关 编码问题
请说明python2 与python3中的默认编码是什么?
python 2.x默认的字符编码是ASCII,默认的文件编码也是ASCIIpython 3.x默认的字符编码是unicode,默认的文件编码也是utf-8
为什么会出现中文乱码?你能列举出现乱码的情况有哪几种?
无论以什么编码在内存里显示字符,存到硬盘上都是2进制,所以编码不对,程序就会出错了。(ascii编码(美国),GBK编码(中国),shift_JIS编码(日本),,,,)要注意的是,存到硬盘上时是以何种编码存的,再从硬盘上读出来时,就必须以何种编码读,要不然就乱了。。 常见的编码错误的原因有: python解释器的默认编码 Terminal使用的编码 python源文件文件编码 操作系统的语言设置,掌握了编码之前的关系后,挨个排错就ok
如何进行编码转换?
#答 :字符串在python内部中是采用unicode的编码方式,所以其他语言先decode转换成unicode编码
#-*-coding:utf-8-*- 的作用是什么?
#答: 编码声明
解释py2 bytes vs py3 bytes的区别
Python 2 将 strings 处理为原生的 bytes 类型,而不是 unicode,Python 3 所有的 strings 均是 unicode 类型。
文件处理
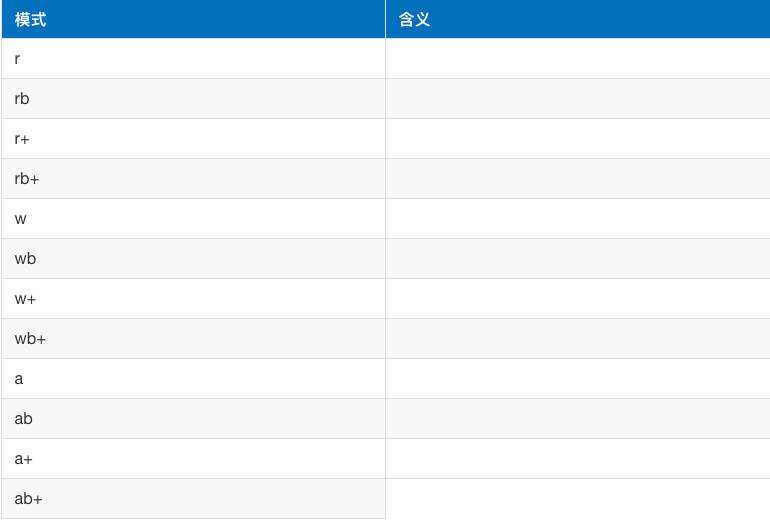
r和rb的区别是什么?
rb,直接读取文件保存时原生的0101010,在Python中用字节类型表示 r和encoding,读取硬盘的0101010,并按照encoding指定的编码格式进行断句,再将“断句”后的每一段0101010转换成unicode的 010101010101,在Python中用字符串类型表示
解释一下以下三个参数的分别作用 open(f_name,'r',encoding="utf-8")
文件路径,打开模式读/写,指定编码
函数基础: 写函数,计算传入数字参数的和。(动态传参)
def num (*args): print(sum(args))num(1,2,3)
写函数,用户传入修改的文件名,与要修改的内容,执行函数,完成整个文件的批量修改操作
import os file_name = "print_tofile.txt"file_new_name = '%s.new' %file_name old_str = '最近学习不太好'new_str = '最近学习真不好' f_old = open(file_name,'r',encoding='utf-8')f_new = open(file_new_name,'w',encoding='utf-8') for line in f_old: if old_str in line: line = line.replace(old_str,new_str) f_new.write(line) print(line)f_old.close()f_new.close()os.replace(file_new_name,file_name)
import osdef update_func(a: object, old_str: object, new_str: object) -> object: #定义三个接受值的形参,a是要修改的文件名,b是要修改的内容,c是修改后的内容 #打开文件,文件名为接受的形参a file_old = 'a.txt' file_new = 'aa.txt' f_old = open(file_old,'r',encoding='utf-8') #打开修改后写入的文件 f_new = open(file_new,'w',encoding='utf-8') # old_str = '你是我唯一的爱' # new_str = 'you are my everything' #循环每一行的文件的数据 for line in f_old: new_content = line.replace(old_str,new_str) #将要修改的内容字符串用replace替换 f_new.write(new_content) #将替换后的内容写入修改后写入的文件中 f_new.close() f_old.close() os.replace(file_new,file_old) update_func('a.txt','你是我唯一的爱','you are my everything') 写函数,检查用户传入的对象(字符串、列表、元组)的每一个元素是否含有空内容。
def check_str(a): #a为传过来的参数 calc = False #空格统计默认False没有 for line in a: if line.isspace(): calc = True return calc a = '123 132 456 7489 456'res = check_str(a)print(res)
def func(strr,listt,tuplee): if strr.isspace(): print("字符串有空内容") else: print("字符串里面没有空内容") if len(listt) ==0: print("列表有空内容") else: print("列表里面没有空内容") if len(tuplee) == 0: print("元祖有空内容") else: print("元组里面没有空内容") res = func('123456',[],())# 字符串里面没有空内容# 列表有空内容# 元祖有空内容 写函数,检查传入字典的每一个value的长度,如果大于2,那么仅保留前两个长度的内容,并将新内容返回给调用者。
dic = {"k1": "v1v1", "k2": [11,22,33,44]} PS:字典中的value只能是字符串或列表
解释闭包的概念
闭包就是一个内部函数+外部环境
函数进阶: 写函数,返回一个扑克牌列表,里面有52项,每一项是一个元组 例如:[(‘红心’,2),(‘草花’,2), …(‘黑桃A’)]
"""2-9JQKA"""card = []def form(key): for card_type in ["红桃","方块","梅花","黑桃"]: res = (card_type,key) card.append(res)if __name__ == '__main__': poker = [str(x) for x in range(2, 11)] # 列表生成式;数字转str poker.extend(["J", "Q", "K", "A"]) # 追加多个元素 for x in poker: form(x)print(card)
写函数,传入n个数,返回字典{‘max’:最大值,’min’:最小值} 例如:min_max(2,5,7,8,4) 返回:{‘max’:8,’min’:2}
def min_max(*args): max_num = max(args) min_num = min(args) return ("max:%d,min:%d" % (max_num,min_num))print(min_max(2,5,7,8,4)) 写函数,专门计算图形的面积
其中嵌套函数,计算圆的面积,正方形的面积和长方形的面积 调用函数area(‘圆形’,圆半径) 返回圆的面积 调用函数area(‘正方形’,边长) 返回正方形的面积 调用函数area(‘长方形’,长,宽) 返回长方形的面积 def area():
def 计算长方形面积(): pass def 计算正方形面积(): pass def 计算圆形面积(): pass
import mathprint('''请按照如下格式输出: 调用函数area(‘圆形’,圆半径) 返回圆的面积 调用函数area(‘正方形’,边长) 返回正方形的面积 调用函数area(‘长方形’,长,宽) 返回长方形的面积''')def area(name,*args): def areas_rectangle(x,y): return ("长方形的面积为:",x*y) def area_square(x): return ("正方形的面积为:",x**2) def area_round(r): return ("圆形的面积为:",math.pi*r*r) if name =='圆形': return area_round(*args) elif name =='正方形': return area_square(*args) elif name =='长方形': return areas_rectangle(*args)print(area('长方形', 3, 4))print(area('圆形', 3))print(area('正方形', 3))# 请按照如下格式输出:# 调用函数area(‘圆形’,圆半径) 返回圆的面积# 调用函数area(‘正方形’,边长) 返回正方形的面积# 调用函数area(‘长方形’,长,宽) 返回长方形的面积# ('长方形的面积为:', 12)# ('圆形的面积为:', 28.274333882308138)# ('正方形的面积为:', 9)复制代码 写函数,传入一个参数n,返回n的阶乘
例如:cal(7) 计算7654321
# 7*6*5*4*3*2*1 阶乘def cal(n): if n == 1: return 1 return n * cal(n-1)print( cal(7) )
编写装饰器,为多个函数加上认证的功能(用户的账号密码来源于文件),要求登录成功一次,后续的函数都无需再输入用户名和密码
def login(func): def wrapper(*args,**kwargs): username = input("account:").strip() password = input("password:").strip() with open('userinfo.txt','r',encoding='utf-8') as f: userinfo = f.read().strip(',') userinfo = eval(userinfo) print(userinfo) if username in userinfo['name'] and password in userinfo['password']: print("success") else: print("pass") return wrapper@logindef name(): print("hello")name() 写一个计算每个程序执行时间的装饰器
import timedef timer(func): def wrapper(*args,**kwargs): start_time = time.time() func(*args) stop_time = time.time() d_time = stop_time-start_time print(d_time) return wrapper@timerdef sayhi(): print("hello word")sayhi() 生成器和迭代器 生成器和迭代器的区别?
1.列表,字典等集合数据类型都是可以迭代的对象:Iterable什么是迭代器:可以被next()函数调用并不断返回下一个值的对象称为迭代器:Iterator2. 生成器是特殊的迭代器li = [x for x in range(20,25)]print(li,type(li))#列表生成式li = iter([x for x in range(20,25)])print(li,type(li))#列表迭代器li = (x for x in range(20,25))print(li,type(li))#生成器
生成器有几种方式获取value?
for 循环 next 获取
通过生成器写一个日志调用方法, 支持以下功能
根据指令向屏幕输出日志 根据指令向文件输出日志 根据指令同时向文件&屏幕输出日志 以上日志格式如下
2017-10-19 22:07:38 [1] test log db backup 32017-10-19 22:07:40 [2] user alex login success
#注意:其中[1],[2]是指自日志方法第几次调用,每调用一次输出一条日志
代码结构如下
def logger(filename,channel='file'): """ 日志方法 :param filename: log filename :param channel: 输出的目的地,屏幕(terminal),文件(file),屏幕+文件(both) :return: ...your code... """ #调用 log_obj = logger(filename="web.log",channel='both') log_obj.__next__() log_obj.send('user alex login success') 内置函数 用map来处理字符串列表,把列表中所有人都变成sb,比方alex_sb name=['alex','wupeiqi','yuanhao','nezha']
name=['alex','wupeiqi','yuanhao','nezha']l = list (map(lambda x:x+"_sb",name))print(l)
name=['alex','wupeiqi','yuanhao','nezha']def change_name(name): res =[ x+"_sb" for x in name] return resa =change_name(name)print(a )
用filter函数处理数字列表,将列表中所有的偶数筛选出来
num = [1,3,5,6,7,8]
num = [1,3,5,6,7,8]f = list(filter(lambda x:x%2 == 0,num))print(f)
def func(x): if x%2 == 0: return True ret = filter(func,num)print(list(ret))
如下,每个小字典的name对应股票名字,shares对应多少股,price对应股票的价格
portfolio = [ {'name': 'IBM', 'shares': 100, 'price': 91.1}, {'name': 'AAPL', 'shares': 50, 'price': 543.22}, {'name': 'FB', 'shares': 200, 'price': 21.09}, {'name': 'HPQ', 'shares': 35, 'price': 31.75}, {'name': 'YHOO', 'shares': 45, 'price': 16.35}, {'name': 'ACME', 'shares': 75, 'price': 115.65} ] 计算购买每支股票的总价
用filter过滤出,单价大于100的股票有哪些
m = map(lambda y:y['shares']*y['price'],portfolio)print(list(m))# [9110.0, 27161.0, 4218.0, 1111.25, 735.7500000000001, 8673.75] a = []for index,i in enumerate(portfolio): res= i['shares'] * i['price'] a.append(res)print(a)# [9110.0, 27161.0, 4218.0, 1111.25, 735.7500000000001, 8673.75]
f = filter(lambda d:d['price']>=100,portfolio)print(list(f))# [{'name': 'AAPL', 'shares': 50, 'price': 543.22}, {'name': 'ACME', 'shares': 75, 'price': 115.65}] lambda是什么?请说说你曾在什么场景下使用lambda?
lambda函数就是可以接受任意多个参数(包括可选参数)并且返回单个表达式值得函数 好处: 1.lambda函数比较轻便,即用即扔,适合完成只在一处使用的简单功能 2.匿名函数,一般用来给filter,map这样的函数式编程服务 3.作为回调函数,传递给某些应用,比如消息处理
什么是装饰器?,写一个计算每个程序执行时间的装饰器;
装饰器模式(Decorator Pattern)允许向一个现有的对象添加新的功能,同时又不改变其结构。这种类型的设计模式属于结构型模式,它是作为现有的类的一个包装。 这种模式创建了一个装饰类,用来包装原有的类,并在保持类方法签名完整性的前提下,提供了额外的功能。
1、请分别介绍文件操作中不同的打开方式之间的区别:
2、有列表 li = ['alex', 'egon', 'smith', 'pizza', 'alen'], 请将以字母“a”开头的元素的首字母改为大写字母;
newl= list(map(lambda x:x[0].upper()+x[1:] ,name))print (newl)
3、有如下程序, 请给出两次调用show_num函数的执行结果,并说明为什么:
num = 20def show_num(x=num): print(x) show_num() num = 30 show_num()
num =20 # 局部变量 作用域问题
4、有列表 li = ['alex', 'egon', 'smith', 'pizza', 'alen'], 请以列表中每个元素的第二个字母倒序排序;
sorted(name,key=lambda x:x[1],reverse=True)
5、有名为poetry.txt的文件,其内容如下,请删除第三行;
昔人已乘黄鹤去,此地空余黄鹤楼。
黄鹤一去不复返,白云千载空悠悠。
晴川历历汉阳树,芳草萋萋鹦鹉洲。
日暮乡关何处是?烟波江上使人愁。
lines = []def txt (file): global lines with open(file, 'r') as f: lines = f.readlines() return linestxt('poetry.txt')with open('poetry2.txt','w') as f: for line in lines: if '晴川' in line: pass else: f.write(line) 6、有名为username.txt的文件,其内容格式如下,写一个程序,判断该文件中是否存在"alex", 如果没有,则将字符串"alex"添加到该文件末尾,否则提示用户该用户已存在;
pizza alex egon
def check_file(file): with open(file,'r+') as f: if 'alex' in f.readlines(): print('exist') else: f.write('\nalex')check_file('username.txt') 7、有名为user_info.txt的文件,其内容格式如下,写一个程序,删除id为100003的行;
pizza,100001 alex, 100002 egon, 100003
8、有名为user_info.txt的文件,其内容格式如下,写一个程序,将id为100002的用户名修改为alex li;
pizza,100001 alex, 100002 egon, 100003
import oswith open("user_info.txt","r") as f1: with open("user_info2.txt", "w") as f2: read = f1.readlines() for line in read: if "100002" in line: pass else: f2.write(line)os.replace("user_info2.txt","user_info.txt") 9、写一个计算每个程序执行时间的装饰器;
import timedef runtime(func): import time def inner(*args,**kwargs): start_time = time.time() func(*args,**kwargs) end_time = time.time() r_time = end_time -start_time print(r_time) return inner@runtimedef echo (): time.sleep(1) print('ok')echo() 10、lambda是什么?请说说你曾在什么场景下使用lambda?
f2=lambda x,y:x*yf2(2,3)num = [1,3,5,6,7,8]f = list(filter(lambda x:x%2 == 0,num))
11、题目:写一个摇骰子游戏,要求用户压大小,赔率一赔一。 要求:三个骰子,摇大小,每次打印摇骰子数。
import random# print(random.randrange(1,7))# 掷骰子person_price = '100'result = []def boll(): result.clear() for i in range(3): n = random.randrange(1, 7) result.append(n) return resultdef start_game(): your_money = 1000 while your_money > 0: print('----- 游戏开始 -----') choices = ["大", "小"] your_choice = input("请下注, 大 or 小:\n") your_bet = input("下注金额:") if your_choice in choices: result_new = '大' if sum(boll()) > 10 else "小" print("结果:%s,点数:%s" % (result_new,result)) you_win = your_choice == result_new if you_win: your_money = your_money + int(your_bet) print("猜中了! 钱包:%d" % your_money) else: your_money = your_money - int(your_bet) print("猜错了~ 余额:%d" % your_money) else: print("穷光蛋了,不玩了")start_game() 作业 现要求你写一个简单的员工信息增删改查程序,需求如下:
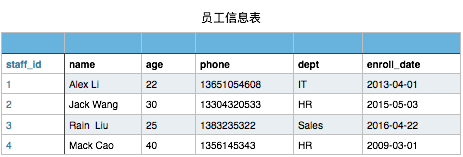
当然此表你在文件存储时可以这样表示
1,Alex Li,22,13651054608,IT,2013-04-01 2,Jack Wang,28,13451024608,HR,2015-01-07 3,Rain Wang,21,13451054608,IT,2017-04-01 4,Mack Qiao,44,15653354208,Sales,2016-02-01 5,Rachel Chen,23,13351024606,IT,2013-03-16 6,Eric Liu,19,18531054602,Marketing,2012-12-01 7,Chao Zhang,21,13235324334,Administration,2011-08-08 8,Kevin Chen,22,13151054603,Sales,2013-04-01 9,Shit Wen,20,13351024602,IT,2017-07-03 10,Shanshan Du,26,13698424612,Operation,2017-07-02 1.可进行模糊查询,语法至少支持下面3种查询语法:
find name,age from staff_table where age > 22
find * from staff_table where dept = "IT"
find * from staff_table where enroll_date like "2013" 2.可创建新员工纪录,以phone做唯一键(即不允许表里有手机号重复的情况),staff_id需自增
语法: add staff_table Alex Li,25,134435344,IT,2015-10-29 3.可删除指定员工信息纪录,输入员工id,即可删除
语法: del from staff_table where id=3 4.可修改员工信息,语法如下:
UPDATE staff_table SET dept="Market" WHERE dept = "IT" 把所有dept=IT的纪录的dept改成Market UPDATE staff_table SET age=25 WHERE name = "Alex Li" 把name=Alex Li的纪录的年龄改成25 5.以上每条语名执行完毕后,要显示这条语句影响了多少条纪录。 比如查询语句 就显示 查询出了多少条、修改语句就显示修改了多少条等。
注意:以上需求,要充分使用函数,请尽你的最大限度来减少重复代码!
答: 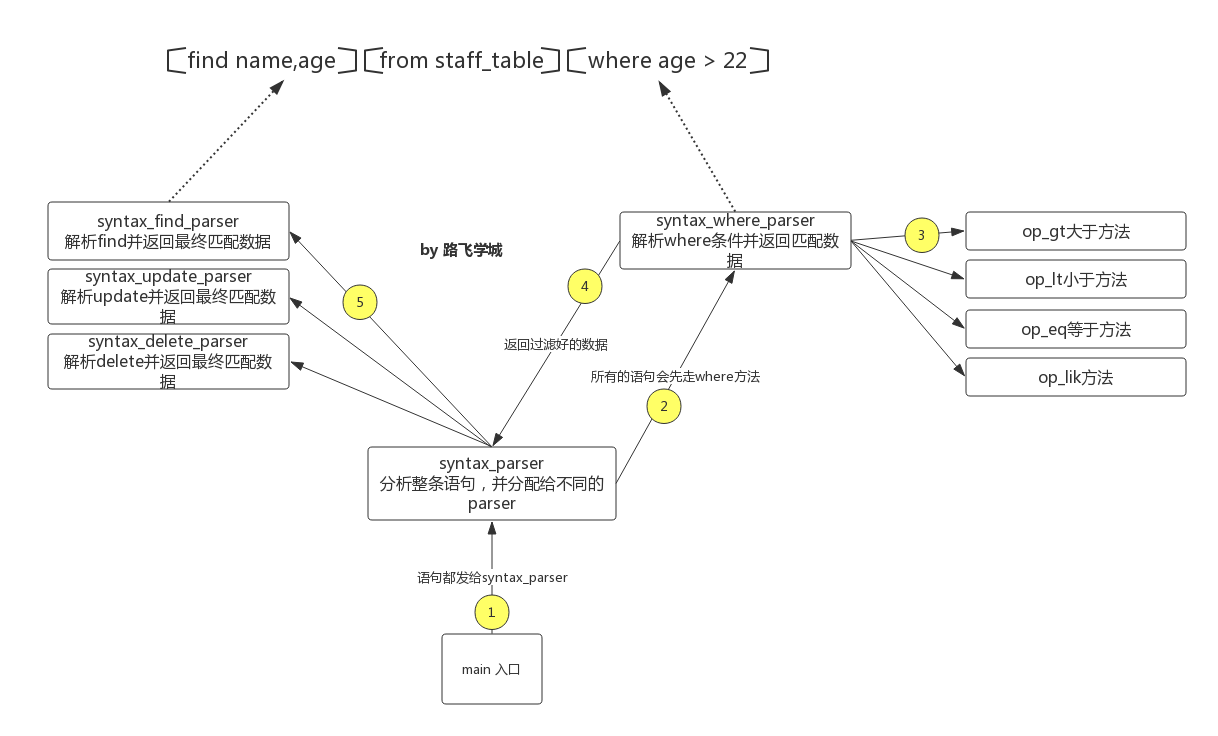 标准答案:
标准答案:
# _*_coding:utf-8_*_# created by Alex Li on 10/15/17from tabulate import tabulateimport osSTAFF_DB = "staff.db" #因为不会变,所以是常量COLUMN_ORDERS = ['id','name','age','phone','dept','enrolled_date']def load_db(): """ 打开db文件,把文件里的数据的每列转换成一个列表 1,Alex Li,22,13651054608,IT,2013-04-01 :return: """ staff_data = { #把文件里的每列添加到下面这些列表里 'id':[], 'name':[], 'age':[], 'phone':[], 'dept':[], 'enrolled_date':[] } f = open(STAFF_DB,"r",encoding="utf-8") for line in f: staff_id,name,age,phone,dept,enrolled_date = line.strip().split(',') staff_data['id'].append(staff_id) staff_data['name'].append(name) staff_data['age'].append(age) staff_data['phone'].append(phone) staff_data['dept'].append(dept) staff_data['enrolled_date'].append(enrolled_date) #print(staff_data) f.close() return staff_datadef save_db(): """sync data back to db each time after editing""" f = open("%s_tmp"%STAFF_DB, "w", encoding="utf-8") for index,val in enumerate(STAFF_DATA[COLUMN_ORDERS[0]]): row = [str(val)] for col in COLUMN_ORDERS[1:]: row.append(str(STAFF_DATA[col][index]) ) raw_row = ",".join(row) f.write(raw_row+"\n") f.close() os.rename("%s_tmp"%STAFF_DB,STAFF_DB)def print_log(msg,msg_type='info'): if msg_type == 'error': print("\033[31;1mError:%s\033[0m"%msg) else: print("\033[32;1mInfo:%s\033[0m"%msg)def syntax_find(query_clause, matched_data): """ :param query_clause: eg. find age,name from staff_table :param matched_data: where方法匹配到的数据 :return: """ filter_keys = query_clause.split('find')[1].split('from')[0] columns = [i.strip() for i in filter_keys.split(',')] #要过滤出来的字段 if "*" in columns: if len(columns) == 1: #只有find * from ...成立,*不能与其它字段同时出现 columns = COLUMN_ORDERS else: print_log("*不能同时与其它字段出现","error") return False if len(columns) == 1: if not columns[0]: print_log("语法错误,find和from之间必须跟字段名或*","error") return False filtered_data = [] for index,val in enumerate(matched_data[columns[0]]): #拿要查找的多列的第一个元素,[name,age,dept],拿到name,到数据库匹配,然后按这一列的每个值 的索引到其它列表里依次找 row = [val,] #if columns[1:]: #代表是多列过滤 for col in columns[1:]: row.append(matched_data[col][index]) #print("row",row) filtered_data.append(row) print(tabulate(filtered_data,headers=columns,tablefmt="grid")) print_log("匹配到%s条纪录"%len(filtered_data))def syntax_add(query_clause, matched_data): """ sample: add staff Alex Li,25,134435344,IT,2015-10-29 :param query_clause: add staff Alex Li,25,134435344,IT,2015-10-29 :param matched_data: :return: """ column_vals = [ col.strip() for col in query_clause.split("values")[1].split(',')] #print('cols',column_vals) if len(column_vals) == len(COLUMN_ORDERS[1:]): #不包含id,id是自增 #find max id first , and then plus one , becomes the id of this new record init_staff_id = 0 for i in STAFF_DATA['id']: if int(i) > init_staff_id: init_staff_id = int(i) init_staff_id += 1 #当前最大id再+1 STAFF_DATA['id'].append(init_staff_id) for index,col in enumerate(COLUMN_ORDERS[1:]): STAFF_DATA[col].append( column_vals[index] ) else: print_log("提供的字段数据不足,必须字段%s"%COLUMN_ORDERS[1:],'error') print(tabulate(STAFF_DATA,headers=COLUMN_ORDERS)) save_db() print_log("成功添加1条纪录到staff_table表")def syntax_update(query_clause, matched_data): passdef syntax_delete(query_clause, matched_data): passdef op_gt(q_name,q_condtion): """ find records q_name great than q_condtion :param q_name: 查找条件key :param q_condtion: 查找条件value :return: """ matched_data = {} #把符合条件的数据都放这 for k in STAFF_DATA: matched_data[k] = [] q_condtion = float(q_condtion) for index,i in enumerate(STAFF_DATA[q_name]): if float(i) > q_condtion : for k in matched_data: matched_data[k].append( STAFF_DATA[k][index] ) #把匹配的数据都 添加到matched_data里 #print("matched:",matched_data) return matched_datadef op_lt(): """ less than :return: """def op_eq(): """ equal :return: """def op_like(q_name,q_condtion): """ find records where q_name like q_condition :param q_name: 查找条件key :param q_condtion: 查找条件value :return: """ matched_data = {} #把符合条件的数据都放这 for k in STAFF_DATA: matched_data[k] = [] for index,i in enumerate(STAFF_DATA[q_name]): if q_condtion in i : for k in matched_data: matched_data[k].append( STAFF_DATA[k][index] ) #把匹配的数据都 添加到matched_data里 #print("matched:",matched_data) return matched_datadef syntax_where(clause): """ 解析where条件,并查询数据 :param clause: where条件 , eg. name=alex :return: False or matched data dict """ query_data = {} #存储查询出来的结果 operators = {'>':op_gt, '<':op_lt, '=':op_eq, 'like':op_like} query_condtion_matched = False #如果匹配语句都没匹配上 for op_key,op_func in operators.items(): if op_key in clause: q_name,q_condition = clause.split(op_key) #print("query:",q_name,q_condition) if q_name.strip() in STAFF_DATA: matched_data = op_func(q_name.strip(),q_condition.strip()) #调用对应的方法 return matched_data else: print_log("字段'%s' 不存在!"%q_name,'error') return False if not query_condtion_matched: print("\033[31;1mError:语句条件%s不支持\033[0m"%clause) return Falsedef syntax_parser(cmd): """ 解析语句 :return: """ syntax_list = { 'find':syntax_find, 'add':syntax_add, 'update':syntax_update, 'delete':syntax_delete, } if cmd.split()[0] in ['find','add','update','delete'] and "staff_table" in cmd : if 'where' in cmd: query_cmd,where_clause = cmd.split("where") matched_data = syntax_where(where_clause.strip()) if matched_data: #有匹配结果 action_name = cmd.split()[0] syntax_list[action_name](query_cmd,matched_data) #调用对应的action方法 else: syntax_list[cmd.split()[0]](cmd, STAFF_DATA) #没where,使用所有数据 else: print_log('''语法错误!\nsample:[find/add/update/delete] name,age from [staff_table] where [id][>/ 常用模块
练习题 logging模块有几个日志级别? 请配置logging模块,使其在屏幕和文件里同时打印以下格式的日志
2017-10-18 15:56:26,613 - access - ERROR - account [1234] too many login attempts json、pickle、shelve三个区别是什么?
json的作用是什么? subprocess执行命令方法有几种? 为什么要设计好目录结构? 打印出命令行的第一个参数。例如:
python argument.py luffy 打印出 luffy 代码如下:
''' Linux当前目录/usr/local/nginx/html/ 文件名:index.html ''' import os BASE_DIR = os.path.dirname(os.path.dirname(os.path.abspath(index.html))) print(BASE_DIR) 打印的内容是什么? os.path.dirname和os.path.abspath含义是什么? 通过configparser模块完成以下功能
文件名my.cnf
[DEFAULT]
[client] port = 3306 socket = /data/mysql_3306/mysql.sock
[mysqld] explicit_defaults_for_timestamp = true port = 3306 socket = /data/mysql_3306/mysql.sock back_log = 80 basedir = /usr/local/mysql tmpdir = /tmp datadir = /data/mysql_3306 default-time-zone = '+8:00' 修改时区 default-time-zone = '+8:00' 为 校准的全球时间 +00:00 删除 explicit_defaults_for_timestamp = true 为DEFAULT增加一条 character-set-server = utf8 写一个6位随机验证码程序(使用random模块),要求验证码中至少包含一个数字、一个小写字母、一个大写字母.
利用正则表达式提取到 luffycity.com ,内容如下
<!DOCTYPE html>
<html lang="en"> <head> <meta charset="UTF-8"> <title>luffycity.com</title> </head> <body> </body> </html> 写一个用户登录验证程序,文件如下 1234.json
{"expire_date": "2021-01-01", "id": 1234, "status": 0, "pay_day": 22, "password": "abc"} 用户名为json文件名,密码为 password。 判断是否过期,与expire_date进行对比。 登陆成功后,打印“登陆成功”,三次登陆失败,status值改为1,并且锁定账号。 把第12题三次验证的密码进行hashlib加密处理。即:json文件保存为md5的值,然后用md5的值进行验证。
最近luffy买了个tesla,通过转账的形式,并且支付了5%的手续费,tesla价格为75万。文件为json,请用程序实现该转账行为。 需求如下:
目录结构为 . ├── account │ ├── luffy.json │ └── tesla.json └── bin └── start.py 当执行start.py时,出现交互窗口
------- Luffy Bank ---------
- 账户信息
- 转账 选择1 账户信息 显示luffy的当前账户余额。 选择2 转账 直接扣掉75万和利息费用并且tesla账户增加75万 对上题增加一个需求:提现。 目录结构如下
. ├── account │ └── luffy.json ├── bin │ └── start.py └── core └── withdraw.py 当执行start.py时,出现交互窗口
------- Luffy Bank ---------
- 账户信息
- 提现 选择1 账户信息 显示luffy的当前账户余额和信用额度。 选择2 提现 提现金额应小于等于信用额度,利息为5%,提现金额为用户自定义。 尝试把上一章的验证用户登陆的装饰器添加到提现和转账的功能上。
对第15题的用户转账、登录、提现操作均通过logging模块记录日志,日志文件位置如下
. ├── account │ └── luffy.json ├── bin │ └── start.py └── core | └── withdraw.py └── logs └── bank.log 本章作业: 模拟实现一个ATM + 购物商城程序
额度 15000或自定义 实现购物商城,买东西加入 购物车,调用信用卡接口结账 可以提现,手续费5% 支持多账户登录 支持账户间转账 记录每月日常消费流水 提供还款接口 ATM记录操作日志 提供管理接口,包括添加账户、用户额度,冻结账户等。。。 用户认证用装饰器 示例代码
简易流程图:
参考: